傳統(tǒng)GPU驅(qū)動(dòng)模型的能耗困境
當(dāng)前主流大語言模型(LLM)如ChatGPT依賴GPU芯片進(jìn)行訓(xùn)練與推理疮肿,此類模型在處理海量數(shù)據(jù)時(shí)需要強(qiáng)大算力支撐奖朴,導(dǎo)致能耗問題日益凸顯呆淑。數(shù)據(jù)中心為支持聊天機(jī)器人等應(yīng)用消耗大量電力,引發(fā)業(yè)界對(duì)可持續(xù)發(fā)展的擔(dān)憂曼刀。研究團(tuán)隊(duì)針對(duì)這一痛點(diǎn)展開技術(shù)攻關(guān)罗卿,提出更智能的數(shù)據(jù)處理方法。
1位架構(gòu)實(shí)現(xiàn)算力優(yōu)化
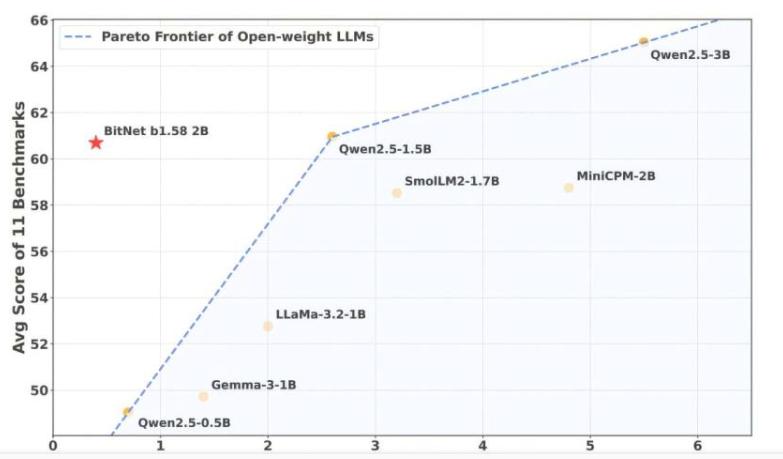
新模型摒棄傳統(tǒng)8位或16位浮點(diǎn)數(shù)存儲(chǔ)權(quán)重的方式魂务,轉(zhuǎn)而采用“1位架構(gòu)”在刺。其核心創(chuàng)新在于將模型權(quán)重簡化為-1、0头镊、1三種離散值蚣驼,使推理過程僅需基礎(chǔ)加減法運(yùn)算。這種設(shè)計(jì)極大降低了內(nèi)存占用與CPU處理負(fù)擔(dān),實(shí)驗(yàn)數(shù)據(jù)顯示該架構(gòu)在保持性能的同時(shí)颖杏,內(nèi)存需求減少至傳統(tǒng)方案的1/16纯陨,能耗降低超90%。研究團(tuán)隊(duì)強(qiáng)調(diào)留储,此方法使普通計(jì)算機(jī)或移動(dòng)設(shè)備即可運(yùn)行高效AI模型翼抠,無需依賴專業(yè)GPU硬件。
BitNet b1.58模型與專用運(yùn)行環(huán)境
為適配1位架構(gòu)获讳,團(tuán)隊(duì)開發(fā)了配套運(yùn)行時(shí)環(huán)境bitnet.cpp阴颖。該系統(tǒng)針對(duì)離散權(quán)重矩陣優(yōu)化內(nèi)存分配與指令調(diào)度,支持20億參數(shù)規(guī)模的模型在單核CPU上穩(wěn)定運(yùn)行丐膝。測(cè)試結(jié)果表明孽衩,新模型在CPU環(huán)境下的推理速度接近傳統(tǒng)GPU方案,且模型精度損失控制在可接受范圍內(nèi)焕徽。在MNIST陌沟、GLUE等基準(zhǔn)測(cè)試中亏拉,其性能表現(xiàn)與同類GPU模型相當(dāng)驮俗,部分場景下甚至實(shí)現(xiàn)超越。
本地化部署提升隱私與能效
該技術(shù)突破為AI應(yīng)用帶來雙重價(jià)值誓贝。在隱私保護(hù)層面肘勾,用戶數(shù)據(jù)無需上傳云端即可完成處理呻蚪,支持完全離線的智能助手開發(fā)。研究團(tuán)隊(duì)在樹莓派等邊緣設(shè)備上成功部署聊天機(jī)器人系統(tǒng)箫废,響應(yīng)延遲低于300毫秒锉潜,且支持?jǐn)嗑W(wǎng)運(yùn)行。在能效層面插驾,單個(gè)推理任務(wù)的耗電量較傳統(tǒng)方案減少92%摹色,單次交互能耗不足0.03Wh。這一特性使其在移動(dòng)終端篇裁、物聯(lián)網(wǎng)設(shè)備等場景中具備顯著優(yōu)勢(shì)沛慢。